You may choose to work with one other person in the class for this assignment.
If you choose to do so, your team will submit one assignment and each student will receive the same grade.
You may not consult with anyone other than your partner (and the instructor, of course).
These question may seem a bit fanciful, but considerable research has gone into studying the collected works of authors and discerning patterns. The theory is that each author has a unique way of using words in his or her writing, which identifies that author's works the same way fingerprints identify people. These literary fingerprints not only provide insight into an author's methods, but also can be (and have been) used to identify the author of anonymous or disputed works of literature.
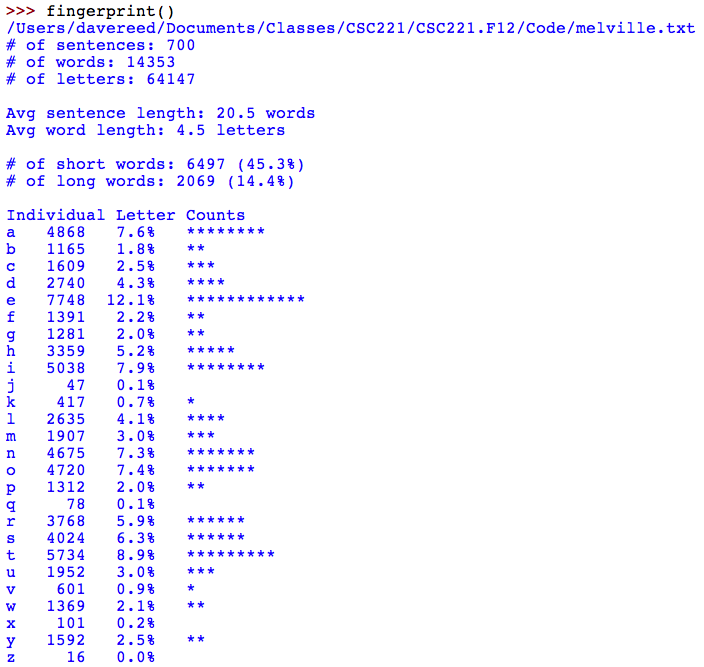
For this assignment, you will write a Python program that analyzes a text file and produces a report describing its literary fingerprint. The output of your code must include:
To make things easier, we will make some simplifying assumptions. We will assume that any word that ends in a punctuation mark, either ".", "?", or "!", designates a sentence. This may lead to some counting errors, such as "I climbed Mt. Shasta." counting as two sentences. Likewise, we will assume that any sequence of characters delineated by whitespace is a word. Again, this might lead to some inaccuracies, such as "He paused - then spoke." counting as a 5-word sentence. However, these counting errors may also balance out, as sentences that end with quotes (e.g., "He said 'stop.'") and hyphen-connected words (e.g., "paused--then") may not be counted.
Finally, note that you are asked to report the number of letters in the file, not the number of characters. You should ignore non-letters (e.g., whitespaces, punctuation marks, digits) when calculating this total. Likewise, the average word length and the definitions of short and long words depend on the number of letters, not the number of characters. This ensures that punctuation marks do not count in word lengths (e.g., "end!" should count as a 3-letter word), but also leads to some surprising results (e.g., "1234" is a 0-letter word).
Your program should use a file dialog window to enable the user to select the text file to be processed. All averages and percentages should be rounded to one decimal place, and all letter frequency stats should be aligned in columns as shown in the sample below:
You should test your code on small files for which you can hand-calculate stats. Once you are confident it works as desired, you can test your code on the following public-domain texts: